Threat Modeling for Software Developers
What level of secrets isolation do we need for AI agents to safely call external APIs? This question came up recently in an architecture discussion at work. We were designing a system where AI agents would call third-party services on behalf of users, and each of those calls might need credentials of some sort. The question seemed straightforward at first. It isn’t.
The answer depends on what you’re protecting, who you’re protecting it from, and what you’re willing to spend (in engineering effort, operational complexity, and actual money) to do it. In other words, it depends on your threat model. Building a threat model is something every developer should know how to do.
The floor
There is a baseline of security practices that every system should implement regardless of context. You don’t need a threat model to decide whether to salt and hash your passwords. You just do it. The same goes for enforcing the principle of least privilege, using TLS for data in transit, validating input at system boundaries, and not hardcoding secrets in your source code.
These are not strategic decisions. They are hygiene. If you’re not doing them, stop reading this and go fix that first. Everything we’re about to discuss assumes you’ve already covered these basics.
The interesting security decisions, the ones that actually require thought and trade-offs, happen above this floor.
Assessing your risk
Back in 2015, I put together a security training course about personal online security. One of the core concepts was a simple risk assessment framework. For any given threat, you evaluate two things: how bad is it if someone pulls it off (impact), and how realistic is it that they will (exploitability).
Plot those on two axes and you get four quadrants. High impact and easy to exploit? That’s your top priority. Low impact and hard to exploit? Probably not worth losing sleep over. The two middle quadrants, high impact but hard to exploit and low impact but easy to exploit, are where judgment calls live.
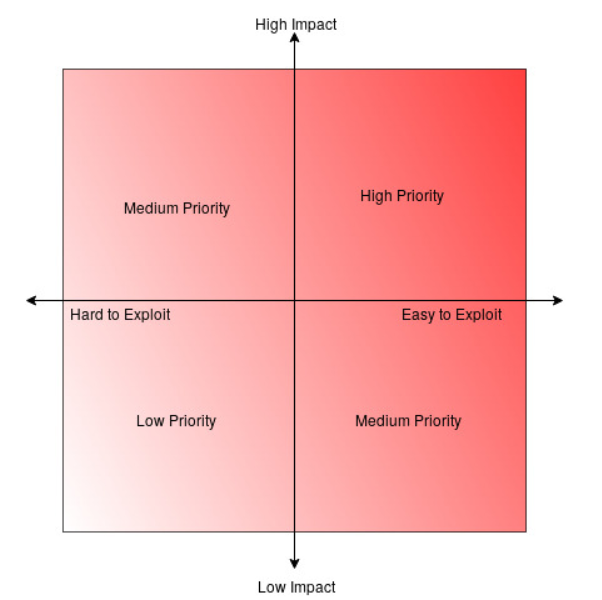
That training was about personal security. Should you enable two-factor authentication on your email? (Yes, high impact and easy to exploit without it.) Should you worry about a nation-state targeting your personal photos? (Probably not, unless you have a very unusual life.) But the framework applies just as well to software architecture decisions. The threats are different, the stakes might be higher, but the thinking process is the same.
This isn’t a novel idea. Security engineers have been saying this for decades. Saltzer and Schroeder’s 1975 paper on information protection defined “economy of mechanism” as a foundational security design principle: keep the design as simple and small as possible. Bruce Schneier put it more bluntly in Secrets and Lies: “Complexity is the worst enemy of security.” The risk matrix is just a practical tool for applying that kind of thinking to specific decisions.
Accept, mitigate, or remediate
Once you’ve assessed where a threat sits on that matrix, you have three choices for how to respond.
Remediate means you eliminate the attack vector entirely. The threat no longer exists because you’ve removed the conditions that made it possible. This is the strongest response, but it isn’t always feasible or worth the cost.
Mitigate means you reduce the impact if the threat is realized. You can’t prevent it, but you can limit the damage. This is often the pragmatic middle ground.
Accept means you acknowledge the risk and decide not to address it. The cost of remediation or mitigation outweighs the expected impact. This sounds scary, but every system accepts some risks. You accept the risk of a meteor hitting your data center because the cost of a meteor-proof data center isn’t justified by the probability.
Each of these responses has costs, and those costs aren’t just about developer time or infrastructure bills. Adding security measures means adding code, and more code means more bugs. Steve McConnell’s Code Complete documents that the industry average is 15 to 50 defects per 1,000 lines of delivered code. That’s not a quality problem specific to any one team. That’s a statistical reality of software development. Every line of security code you write has the same defect rate as every other line of code. Some percentage of those defects will themselves be security vulnerabilities.
This isn’t theoretical. The TLS renegotiation attack (CVE-2009-3555) is a real-world example. TLS renegotiation was a protocol feature designed specifically to improve security. It allowed either side of a connection to request new handshake parameters mid-session, for example requesting a client certificate after initially connecting without one. The added protocol complexity created an attack vector that allowed a man-in-the-middle attacker to inject data into the beginning of a TLS session. It affected virtually every TLS implementation in existence and required an entirely new RFC (RFC 5746) to fix. The simpler design, one that didn’t allow renegotiation at all, would have been more secure.
So when you’re deciding whether to add a security feature, you’re not choosing between “secure” and “insecure.” You’re choosing between different risk profiles, each with its own trade-offs. The question isn’t “is this more secure?” It’s “does the security benefit justify the complexity cost, given our threat model?”
So what about those AI agents?
Let’s come back to the question we started with. AI agents need to call external APIs with credentials. How do we prevent the agent from accessing or leaking those secrets?
First, identify the threats. There are (at least) two distinct ones here, and they sit in very different places on the risk matrix.
Threat 1: The agent exposes or misuses secrets. This is high impact (credential theft or misuse) and relatively easy to exploit (the agent is, by design, an autonomous system executing arbitrary code in response to prompts). LLMs can be manipulated through prompt injection, they can hallucinate tool calls, and they can be tricked into including credentials in their output. This threat sits firmly in the high-priority quadrant.
Threat 2: A sophisticated adversary achieves container escape and reads secrets from memory. This is also high impact (same credential exposure), but it’s hard to exploit. Container escape requires kernel-level vulnerabilities and significant attacker sophistication. This lands in the medium-priority quadrant.
Now apply the three responses.
For Threat 1, the right response is remediate. Eliminate the attack vector entirely. If the agent never has access to credentials, it can’t expose them regardless of what an attacker gets it to do. One way to accomplish this is a secrets proxy: an external process intercepts the agent’s outbound network traffic and injects credentials at the network layer. The agent calls the real API URL using a standard SDK. The proxy adds the authorization header before the request reaches the upstream service. The agent never sees, stores, or transmits a credential.
This is not a novel architecture. It’s the sidecar proxy pattern used by Envoy, Istio, and Linkerd in production Kubernetes environments. The same transparent traffic interception approach that powers service mesh observability works for credential injection. It’s well-understood, battle-tested infrastructure.
For Threat 2, the right response depends on your threat model. You could accept the risk: a container escape is a real possibility but requires significant attacker sophistication, and defending against it adds substantial complexity. For many organizations, the sidecar proxy running alongside the agent in a standard container is sufficient isolation.
Or you could mitigate the impact: run the agent sandbox in a micro-VM using something like Kata Containers, which provides hardware-level isolation between the agent and the host. If an attacker escapes the container, they’re still inside a lightweight virtual machine. This meaningfully reduces the blast radius of a container escape.
But that mitigation isn’t free. Micro-VM isolation is a fundamentally different architecture from standard Kubernetes containers. It changes your scheduling model, your networking, your resource management, and your operational playbook. That’s more code, more configuration, more moving parts, and (per McConnell’s defect density numbers) more bugs. You have to ask whether the additional complexity is more dangerous than the threat it’s defending against.
There’s no universal right answer here. A startup building internal tooling for a small team might reasonably accept the container escape risk and run the sidecar proxy in a standard pod. A financial services company handling customer payment credentials might require the micro-VM isolation. Neither team is wrong. They have different threat models because they’re protecting different things with different consequences for failure.
Security decisions are business decisions
The question we opened with, “what level of secrets isolation do we need for AI agents?”, doesn’t have a technical answer. It has a technical menu of options, each with different security properties and different costs. Choosing from that menu requires understanding the business context: what are we protecting, what is it worth, who are the likely adversaries, and what are the consequences of a breach?
Engineers can and should lay out the options clearly. Here are the threats, here’s where they sit on the risk matrix, here are the available responses, and here’s what each one costs in complexity, maintenance burden, and operational overhead. That analysis is technical work.
But deciding how much risk is acceptable for a given product? That requires input from people who understand the regulatory environment, the customer expectations, the financial exposure, and the competitive landscape. A threat model gives everyone, engineers and business stakeholders alike, a shared framework for having that conversation productively instead of arguing about whether containers are “secure enough.”
Above the baseline, there is no such thing as “secure enough” in the abstract. There is only “appropriate for our threat model.” Getting there starts with asking the right questions: how bad is it if this happens, how likely is it, and what are we willing to spend to address it?
Director of Infrastructure Engineering at OpenTeams. I write about infrastructure, open source, and the occasional career reflection. Based in Granada, Spain.